Before the Transformer: The State of NLP
To understand the significance of the Transformer, it's essential to look back at the state of NLP before its arrival. Prior to 2017, recurrent neural networks (RNNs) dominated sequence modeling tasks. RNNs process data sequentially, one element at a time, maintaining a hidden state that carries information from previous steps.
Variants like Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs) improved upon basic RNNs by addressing the vanishing gradient problem, which made it difficult for models to learn long-term dependencies. These architectures were used in applications ranging from machine translation to speech recognition.
Limitations of Recurrent and Convolutional Models
However, RNNs had inherent limitations. Their sequential nature meant that training and inference were inherently slow because computations couldn't be parallelized effectively. For a sentence with hundreds of words, the model had to process each word one by one, propagating errors and dependencies through time.
This bottleneck became increasingly problematic as datasets grew larger and models aimed for more complex understanding. Researchers experimented with convolutional neural networks (CNNs) for sequences, but these still struggled with capturing global context without deep stacks of layers.
The Introduction of the "Transformer" Model
Enter the Transformer model, introduced in the seminal paper "Attention is All You Need" by Ashish Vaswani and colleagues at Google. Published in June 2017, the paper proposed a radically different architecture that dispensed with recurrence and convolutions entirely, relying instead on attention mechanisms.
The title itself was a bold declaration: attention, not recurrence, was sufficient for state-of-the-art performance in tasks like machine translation. This shift marked a breakthrough because it enabled parallel processing of entire sequences, drastically reducing training times and allowing models to handle much longer inputs.
High-Level Architecture
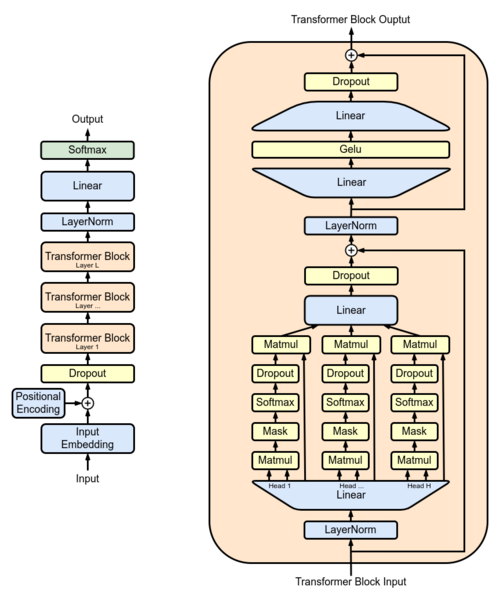
The Transformer's architecture is built around two main blocks: the encoder and the decoder. In a typical setup, like the original for machine translation, the encoder processes the input sequence (e.g., a sentence in English), while the decoder generates the output (e.g., the French translation).
Each consists of stacked layers, usually six in the original model, but scalable to more in modern variants.
Self-Attention: The Core Mechanism
At the heart of the Transformer is the self-attention mechanism. Attention allows the model to weigh the importance of different parts of the input when processing a particular element.
For instance, when translating "The animal didn't cross the street because it was too tired," the model needs to determine that "it" refers to "the animal," not "the street." Self-attention computes this by creating three vectors for each input token: Query (Q), Key (K), and Value (V), derived from the input embeddings via linear transformations.
Scaled Dot-Product Attention
The attention score for a query against a key is calculated using a dot product, scaled by the square root of the dimension to prevent vanishing gradients, and then passed through a softmax to get probabilities.
The output is a weighted sum of the values based on these probabilities. This process happens in parallel for all positions, making it highly efficient.
Attention(Q, K, V) = softmax(QK^T / √d_k) V
Where d_k is the dimension of the keys.
Multi-Head Attention
To capture different types of relationships, the Transformer uses multi-head attention. Instead of a single attention mechanism, it runs several in parallel (e.g., 8 heads), each with its own Q, K, V projections.
The outputs are concatenated and linearly transformed, allowing the model to attend to information from different representation subspaces simultaneously.
Positional Encoding
Another critical innovation is positional encoding. Since the Transformer processes the entire sequence at once without recurrence, it lacks inherent knowledge of order.
To inject positional information, sinusoidal functions are added to the input embeddings:
PE(pos, 2i) = sin(pos / 10000^{2i/d_model})
PE(pos, 2i+1) = cos(pos / 10000^{2i/d_model})
This encoding ensures that relative positions are preserved and can be learned by the model.
Encoder and Decoder Layers
Each encoder layer includes multi-head self-attention followed by a feed-forward network (FFN), with residual connections and layer normalization around each sub-layer.
The FFN is a simple two-layer perceptron with ReLU activation. The decoder mirrors this structure but adds an extra multi-head attention layer that attends to the encoder's output, enabling cross-attention between input and output.
Computational Efficiency and Parallelism
This design's breakthrough lies in its efficiency. Unlike RNNs, where computation time scales linearly with sequence length due to sequential dependencies, Transformers compute attention in O(n^2) time but with constant depth.
This allows massive parallelization on GPUs. Training times dropped from weeks to days, enabling experiments with larger models and datasets.
Transformers as the Foundation of LLMs
In the context of LLMs, the Transformer architecture became the foundation for generative models. OpenAI's GPT (Generative Pre-trained Transformer) series, starting with GPT-1 in 2018, adapted the decoder-only Transformer for autoregressive language modeling.
BERT (Bidirectional Encoder Representations from Transformers), introduced by Google in 2018, used an encoder-only setup with masked language modeling, allowing bidirectional context.
Emergent Abilities
These adaptations highlighted the Transformer's versatility. LLMs like GPT-3, with 175 billion parameters, demonstrated emergent abilities such as few-shot learning, where the model performs tasks with minimal examples.
The breakthrough wasn't just architectural; it was in scalability. Attention's quadratic complexity is manageable with techniques like sparse attention or approximations in models like Reformer or Longformer.
AI Benchmarks and Applications
The impact on AI has been transformative. Pre-Transformer, state-of-the-art NLP models achieved around 70–80% accuracy on benchmarks like GLUE. Post-Transformer, scores soared above 90%, with superhuman performance in many areas.
This enabled real-world applications such as chatbots like ChatGPT, automated translation in Google Translate, content generation, and code writing in tools like GitHub Copilot.
Transformers Everywhere
Transformers extended beyond NLP. Vision Transformers (ViT) apply the architecture to images by treating patches as tokens, rivaling CNNs in computer vision.
Multimodal models like CLIP combine text and vision Transformers for zero-shot image classification. In science, AlphaFold uses Transformers for protein folding prediction, accelerating drug discovery.
Limitations
Despite its strengths, the Transformer isn't without challenges. The O(n^2) attention complexity limits handling very long sequences, though innovations like FlashAttention optimize memory usage.
Energy consumption for training massive LLMs raises environmental concerns, and issues like hallucination—generating plausible but false information—persist.
What the Future Holds
Evolutions include efficient variants like Performer (using random projections for linear attention) and state-space models like Mamba, which aim to combine recurrence benefits with Transformer's parallelism.
Hybrid approaches blending Transformers with other architectures are emerging.
Conclusion
In summary, the Transformer model represents a paradigm shift in AI, dethroning sequential models and it was the technology that enabled the rise of LLMs. Its attention-based design unlocked unprecedented scale and performance, turning science fiction into reality. It truly is the bedrock of modern intelligent systems and until a new breakthrough is achieved, achieving AGI will not happen.
